System Overview
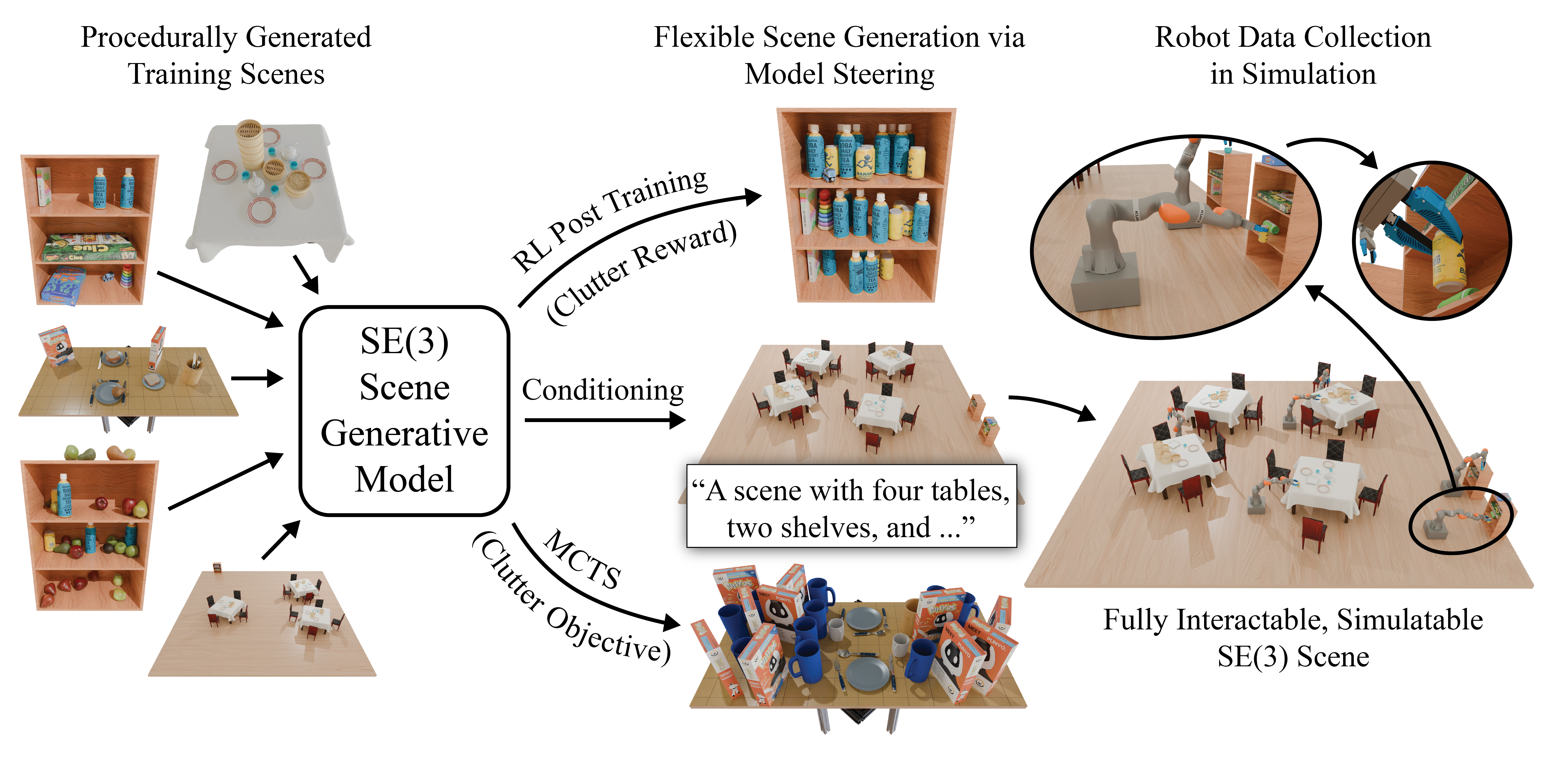
We train a diffusion-based generative model on SE(3) scenes generated by procedural models, then adapt it to downstream objectives via reinforcement learning-based post training, conditional generation, or inference-time search. The resulting scenes are physically feasible and fully interactable. We demonstrate teleoperated interaction in a subset of generated scenes using a mobile KUKA iiwa robot.